
クローリングとは、ページのリンクを辿って新しいWebページのURLやリンクを発見して、別の新しいページに移動し続けることを意味します。リンクを辿って移動し続けるので、Webサイトを巡回するのがクローリングと言い換えることが出来ます。どんな有益なコンテンツもクローリングで発見されなければ、検索結果に表示されることはありません。そのためクローリングはSEOで評価されるために必要な対策項目となっています。
今回の記事では、クローリングの概要やクローラーの種類、おもなクローリング対策についてまとめて解説いたします。


クローリングとは、検索エンジンのロボットであるクローラーがサイト内のリンクをたどって、新しいページを移動し続けることを言います。作成したコンテンツが検索エンジンに知られて検索結果に掲載されるには、必ず「クローリング」が行われています。また、クローラーはWebサイトのHTMLを読み込み、HTML内のリンクを辿ってサイト間を移動しています。蜘蛛の巣のように張り巡らされたリンクを渡り歩く様子から「スパイダー」とも言われています。
クローリングが、リンクのURLを発見して新しいページのリンクを辿り続けるWebサイトの巡回をすることに対して、スプレイピングは収集した情報の抽出を行う点で異なります。Webサイトの統計・及び分析するプロジェクトでは、クローリングとスクレイピング双方の過程を得て行います。混同されやすいので、違いを理解しましょう。
自社サイトの記事がクローリングから検索結果に表示されるまでは、いくつかの工程があります。まず行われるのが、Webサイトのクローリングです。
クローリングされたWebサイトの情報を抽出して検索エンジンのデータベースに格納されます。このデータベースに格納される工程のことをインデックス(インデキシング)といいます。検索エンジンにインデックスされたうえで、検索エンジンのアルゴリズムに基づきコンテンツを評価して、検索キーワードごとに検索結果の表示順位が決まります。
順位づけの基準は明確にはされていませんが、Googleが示す基本の判断基準は「ユーザーにとっていかに有益であるかどうか」です。そのため中身がスカスカな記事は、クローリングされたとしても検索結果の上位には上がらず、ユーザーの目には止まりにくくなります。
Webサイトをクローリングするクローラーは、多くの種類が存在します。多くの検索エンジンは別々のクローラーでWebサイトを巡回しています。ここでは代表的なクローラーの種類を紹介します。
もっとも有名なのは、Googleのクローラー「Googlebot」です。コンピューターの規模も他の追随を許さないレベルなため、一回のクローリングで多くの情報を収集します。そのため、サーバーに負担がかからないのが特徴です。
Googlebot以外にも、主な検索エンジンには下記の名前のクローラーが存在しています。
たとえば、マイクロソフト社の検索エンジンBingの「Bingbot」、中国の検索エンジン百度の「Baiduspider」、韓国で利用される検索エンジンNEVERの「Yetibot」、さらに日本ではおなじみのYahoo!JAPAN「Y!J」などが知られています。
日本国内のユーザーにおいて、Yahoo!とGoogleの検索エンジンを利用しているのが多数を占めています。しかし、Yahoo!の検索エンジンは、Googleのアルゴリズムを利用しています。そのため、日本のサイトオーナーはGoogleのSEO対策に重きを置いてサイト運営をしているケースがほとんどです。
自分が運営するWebサイトが検索エンジンに正しくクローリングされているか確認する方法はあるのでしょうか?次に「初級〜中級」「上級」に分けて、クローリングの状態を確認する流れをお伝えします。
自社サイトがクローリングされているかは、「Google Search Console」を使って知ることができます。Googleサーチコンソールの「インデックス > カバレッジ」でみることができるURLはクローリングされた対象ページになっています。カバレッジ情報を見ることで、インデックスされているかどうかを確認することができます。

特定ページがクローリングできているかを確認する場合は、Googleサーチコンソールの「URL検査」も有効です。対象のページがクローリングできるかを含めて確認することができます。

Googleのクローラーによるサイト巡回の統計情報は、Google Search Consoleの「クロールの統計情報」で確認することができます。クローリングは、SEOの健康診断項目として定点観測が必要です。

1日どのくらい巡回されたのか、期間内の最高値と平均値、最低値が確認できます。さらに1日にクローラーがダウンロードしたデータ量も把握可能です。
クロールの統計情報には、ページのダウンロード時間を見ることができます。ページのダウンロード時間が長すぎると、サーバーの過負荷を回避するため、検索エンジンがクローリングを控えるケースもあります。安定したクローリングを誘導するために、必要な統計上を見ることができます。
上級者向けのクローリング状況の確認方法に生ログの分析があります。生ログを確認することで、どのクローラーがいつ、どのページに訪れたのか、行動や頻度をより詳しくモニタリングすることが出来ます。
また、クローラーに限らず、Googleサーチコンソールだけではわからない情報も生ログで確認できる場合が多くあります。確認方法は、アクセスログをダウンロード後、テキストエディタを開きます。「Googlebot」など、クローラーの名前で検索をかけてヒットすれば、そこからいつどのページに訪れたのかが把握できます。
クローリングはサイトコンテンツを検索エンジンに表示させる、最初の工程です。つまり、SEOの基本の中の基本ともいえます。それにもかかわらず、あまり意識をしていないサイトオーナーが多く、SEOにおいてクローリングはほとんど意識されないポイントです。
正しいクローリング対策で、SEO効果を高めるようにしましょう。
クローリング対策の初歩は、内部リンクの設置でページのリンクを辿って新しいページを辿り続けさせることです。内部リンクがあることで、まだクローリングをしていないページの存在を知ることが出来ます。間違った内部リンクの設置で非効率なクローリングとならないようにSEOに効果的な内部リンク設置を意識するとよいでしょう。
大規模なサイトはクローリングを加味した内部リンク設計によって、サイトのSEO効果が違いますので配慮が必要です。
クローリングして欲しいURLをサイト側から検索エンジンに必要なのは、sitemap.xmlの作成と更新です。sitemap.xmlは、クローリング必要なURLのページや画像・動画情報をリストで検索エンジンに教えることが出来ます。
検索エンジンにsitemap.xmlを知らせるためには、XMLサイトマップ(sitemap.xml)とロボッツテキスト(robots.txt)の記述方法を理解することが必要です。xmlサイトマップを作成した後は、Googleサーチコンソールのサイトマップ送信を行います。
RSSフィードとは、新しいページができたことを、検索エンジンに知らせることができるシステムです。自社サイトに作成をすれば、クローラーが更新情報一覧を素早くチェックし、クローリングが円滑に進みます。
RSSフィードはGoogle Search Consoleに登録ができます。sitemap.xmlの送信と同様の手順で行うことが出来ます。
大きなサイトであればあるほど、リンク切れページが目につきます。
リンク切れが多くあったりリンク先が適切でなかったりする場合、インデックスに登録されなくなります。しかしひとつひとつのリンクを一度に目視でチェックするのは手間なため、リンク切れのチェックツールの使用やこまめなリンクチェックなどを行いましょう。
サーバーが遅いサイトのクローリングを大量にしてしまうと、サーバーを落としてしまうかもしれません。その可能性を考慮して、多くの検索エンジンは表示速度が遅いサイトのクローリング数を抑えます。つまり、表示速度に問題があるサイトは、Googleなどの検索エンジンのクローリングが進まない可能性を持っています。
クローリングだけの問題ではなく、表示速度はSEOの順位に影響しますので表示速度が遅い場合は対策優先度を上げる必要があります。
不要なクローリングを防ぐことで、効率的なクローリングを実現することが可能です。そのため、SEOで価値が無いページは、クローリングをさせない制御をするとよいでしょう。この制御をおこなわない場合は、本来クローリングをさせるべきページのクローリングを妨げてしまう可能性があります。例えば、サイトの公開予定がないページやテスト中のページは、クローラーにそれらを巡回させてインデックスされても、意味がありません。
クローリングの制御方法によってクローリングをさせない方法は以下4つの方法を知っておくとよいでしょう。
HTML内の記述された特定リンクをたどらせないために、アンカーリンクに「no follow」を設定します。no followは、特定リンク先が信頼できない、保証できないなどでGoogleの評価が落ちそうな場合に、<a>タグ内に<a rel=”nofollow” href=””> と記述します。
特定のアンカーリンクをたどらせないのではなく、ページ全てのアンカーリンクにnofollowを設定する場合は、該当するページの<head></head>タグの間に、<meta name=”robots” content=”nofollow”>と記述します。クローリング不要なリンクがある場合に設定しましょう。
robots.txtのファイルをサーバー内に設置することで、クローラーの制御をすることができます。クローリング不要なページをたどらせない制御をすることができるので、効率よいクロールを促すことができます。迷惑なクローラーの制御をすることができるので、サーバー運用保守の観点からrobots.txtの記述方法と設置方法は知っておきましょう。
大手の検索エンジンはクローラーのUA(ユーザーエージェント)を明示していますが、UAを偽装することもできるので迷惑なクローラーを.htaccessのIPアドレスで防ぐことができます。また、テストサイトをクロールさせたくない場合は、ベーシック認証を掛けることで制御することもできます。クリーリングの制御に.htaccessの操作や記述方法の把握は必要です。
クローリングは、クローラーがページ内の情報を収集し、複製・保存することを指します。クローリングが行われないと、そもそも検索結果に記事が掲載されないため非常に重要な役割をしています。
すべてのサイトを定期的に巡回しているわけではなく、収集する情報量も異なります。クローラーはプログラムによって自動化されており、巡回頻度や収集するデータはGoogleのアルゴリズムによって決定されます。
クローラーに対する巡回優先度を伝えていないサイトであったり、クローラー対策の設計が出来ていないケースなどが該当します。クローラーがうまく巡回できるような設計が必要です。
クローラーの巡回頻度と検索順位に直接的な関係性はありませんが、上位表示が出来ているサイトとそうでないサイトで違いが発生している可能性はあります。
クローリングはSEO施策においてとても重要な役割です。クロールエラーやインデックスに登録されないと検索エンジンにサイトが掲載されません。問題が解決できないときはSEOに強い制作会社へ相談しましょう。
クローリングはサイトのSEO効果を最大化するために無視できない存在です、あまり強く意識しているサイトオーナーは少ないかもしれません。円滑にクローリングができる環境をよく道筋をひとつずつ立てて、SEO効果を最大化させるサイト運営を目指しましょう。


サイト運営する上で、注意しなければいけないのがGoogleペナルティです。 Webサイトの流入が急に減った…そんな時、実はGoogleからペ…

Webサイトの記事が増えてくると起こる可能性のある問題が、キーワードのカニバリゼーション(共食い)です。あまり大きく取り上げられる概念ではな…

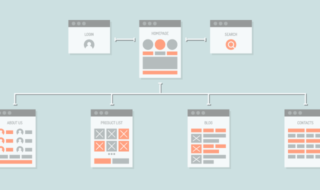
サイトマップとは、「Webサイトの地図」のことで、サイト全体のページ構成を記述しています。サイトマップには、大きく2種類が存在しており、サイ…
SEOで上位表示をするためにも、おすすめしたいのがGoogleサーチコンソールのサイトマップ送信です。 Googleサーチコンソールにサイト…

Googleは、“Core Web Vitals(コアウェブバイタル)”と呼ばれる新たな指標を検索ランキング要因として追加しました。Core…

Googleへのサイト登録は新しくWebサイトを作った時に必須の作業です。新しくWebサイトを作成しただけでは、検索エンジンの検索結果には表…





今話題のAIによるコンテンツ自動生成機能も!SEO対策に本当に必要な機能だけを搭載した使いやすさとコストパフォーマンスに優れたWeb集客支援ツールです。
Webマーケティングに関わる施策全般をワンストップで
ご提供します。
お気軽にご相談ください。
Webマーケティング最新ニュースのレポートや無料セミナーの先行案内が届く、お得なメルマガ配信中!



 検索順位で1位まで上げるためのSEOポイント8つ
検索順位で1位まで上げるためのSEOポイント8つ E-E-A-Tとは? SEOにおける重要性と評価の高め方を解説
E-E-A-Tとは? SEOにおける重要性と評価の高め方を解説 成功確率アップ!BtoBのコンテンツマーケティング施策とは
成功確率アップ!BtoBのコンテンツマーケティング施策とは YMYLとは?該当するジャンルとSEOにおける対策のポイント8つ
YMYLとは?該当するジャンルとSEOにおける対策のポイント8つ SEO内部施策とは?重要な項目16選【セルフチェックリストつき】
SEO内部施策とは?重要な項目16選【セルフチェックリストつき】