
「このページは何に関するページなのか?」
検索エンジンが「何に関するサイト」であるか認識しやすいように、サイトを構築する必要がある。検索エンジンは人間のようにウェブページを読み込むことができないので、ウェブページのコンテンツが何を意味するかを伝えるような構造やヒントを組み込むことで読み込ませる。
そうすることによって、クエリを意味のある検索結果と結びつけるための、検索エンジン最適化の関連性要素を提供する役割を果たすのだ。
この意味を捉えるために適用されるテクニックを理解することで、我々のコンテンツに関連するものに対するよりよいシグナルを提供するのに役立ち、また、最終的にはより高い検索結果のランキングを得ることに役立つのである。この記事では、互いに構築しあうだけでなく、洗練された方法で組み合わせることのできる一連の内部対策テクニックを検証する。
Google は、そのアルゴリズムに関する十分な詳細を公開していないが、我々は、これらのプロセスを検証できるよう、過去数年間に渡り、インタビュー、研究論文、米国の特許出願、および数百名というサーチマーケッターによる所見などからの証拠を収集してきている。そのSEO By the Seaへの記事の投稿がこの作業に関する調査の多くに結びつくこととなった、Bill Slawski氏には特に謝辞を表したい。
読みすすめるにあたり、これから紹介するものは、Googleが内部対策の関連性に関する判断方法の一部であり、それが絶対的な法則ではないということにご留意いただきたい。自分自身で試してみることが最良の策である。
まずは簡単なものから始め、より高度なものを紹介しようと思う。
目次


当初は、キーワードがページの至る所に配置されていた。
このコンセプトは以下の通りであった:ウェブページが特定のトピックに焦点を当てたものである場合、検索エンジンは重要な部分にキーワードを発見する。ここで言う場所というものには、タイトルタグ、ヘッドライン、イメージのalt属性およびテキスト全体が含まれる。SEOは、ページをランク入りさせるために、これらのページ領域にキーワードを配置していた。
今日でも、キーワードから始めており、この手法は依然として内部最適化の最も基本的な形式である。
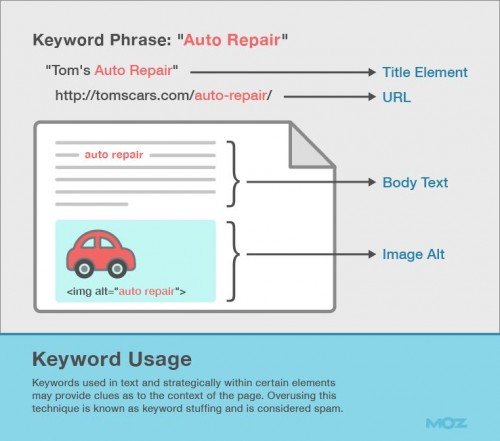
内部SEO用ツールのほとんどは、格付けの際には未だにキーワード配置に依存している。依然としてキーワード配置はよい手始めだが、研究ではその影響力は衰退しているということだ。
確実にランキングの対象としたいキーワードがページに必要最小限含まれていることは重要だが、そのキーワードの配置そのものがページのランキングの可能性に大きな影響を及ぼすことは考えにくい。
これは、キーワード密度ではなく、それはTerm Frequency (単語出現頻度)-Inverse Document Frequency (リバース ドキュメント頻度) (TF-IDF)である。
Googleの研究者は最近TF-IDF法を「長きにわたってウェブページのインデクシングに使用されてきている」としており、また、TF-IDF法の変化形も、数件の著名なGoogleの特許のコンポーネントとして出てきている。
TF-IDFはキーワードの出現頻度を測定するのではなく、キーワードの出現頻度を大量なドキュメントから収集された期待値と比較することで重要度の測定を行うものである。
「バスケット」という語句と「バスケットボール 選手」という語句をGoogleのNgramビューワーで比較すると、「バスケットボール 選手」はより希少であるのに対し、「バスケット」はより一般的であることがわかる。この頻度に基づき、「バスケットボール 選手」はその単語を含んでいるページでは重要であり、その一方で、「バスケット」という単語の閾値ははるかに高い状態であると結論付けることができるだろう。
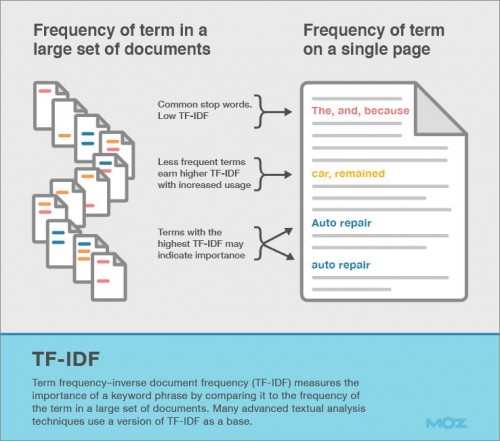
SEO目的では、TF-IDFの関連性をより高いランキングと比較して測定すると、個別のキーワード使用時よりその実績はやや優れているという程度である。言い換えれば、概して高いTF-IDFスコアの創出そのものからは大したSEOの上昇は見込めないということだ。その代わりに、TF-IDF法を、他のより高度な内部対策のコンセプトの重要な構成要素の一部として考える必要がある。
1日あたり60億件を上回る検索件数のあるGoogleには、検索ユーザーが検索ボックスにクエリを入力している時に実際に何を意味しているのかを定める情報を豊富に持っている。Google独自の研究によると、最大70%は類義語で検索されているそうだ。
この問題を解決するために検索エンジンは、検索エンジンのユーザーが、ページとは異なるテキストを使用した場合にもコンテンツをマッチングすることのできる、広大な範囲にわたる類義語のコーパス(言語的な情報)および、何十億にものぼる語句の類似語を有している。ここでは、以下と同じ意味をもつ可能性のある、「犬の写真」のクエリを例にとってみよう。
・Dog Photos(犬 写真) ・Pictures of Dogs(犬の画像) ・Dog Pictures(犬 画像)
・Canine Photos(イヌの写真) ・Dog Photographs(犬のフォトグラフ)
その一方で、「Dog Motion Picture(犬の映画)」というクエリは完全に違うものを意味し、検索エンジンにとってはその違いを知ることが重要なのである。
SEOの観点からは、上記は、徹底的に同じキーワードを何度も何度も繰り返し使う代わりに、同じ自然言語とその変化形を使ってコンテンツを作成することを意味する。
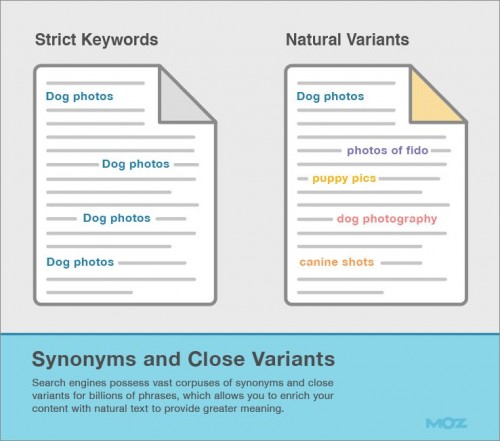
ページの主題の変化形を使うことで、さらに深い意味論的要素を加えることができ、また、キーワード語句が複数の概念を指す場合に、同一のキーワードの曖昧さ回避の問題も解決することができる。Plant(工場)とFactory(工場)はともにManufacturing plant(製造工場)を指す場合もあるが、Plant(植物)とShrub(灌木)は植生を指す。
今日では、GoogleのHummingbirdアルゴリズムもまた、クエリ置換のための類義語を識別するために共起性を使用している。
Hummingbirdでは、共起性は、そのような置換が実施され高度化された可能性があるクエリに対する特定のページの選択に関する特定の規則に従うと同時に、特定のコンテキストにおいて互いに類義語である可能性のある単語を識別するのに使用されている。
SEO by the Sea Bill Slawski氏
ウェブページ内のどこに単語を配置するのかということはしばしば単語そのものと同様に重要である。
各webページは、ヘッダー、フッター、サイドバーを始めとする様々なパーツから構成されている。検索エンジンは、長きにわたって、対象となるページの中で最も重要なパーツを判断するよう、尽力してきている。MicrosoftとGoogleの双方は、より関連性の高いHTMLのセクションのコンテンツがより多く重み付けされるよう示す数件の特許を持っている。
本体テキストに配置されたコンテンツはサイドバーやその他の位置に配置されたテキストよりも高い重要性を持つことが多い。ボイラープレートまたはChromeに配置されたテキストの繰り返しは、ページがさらに軽視されるリスクが発生する。
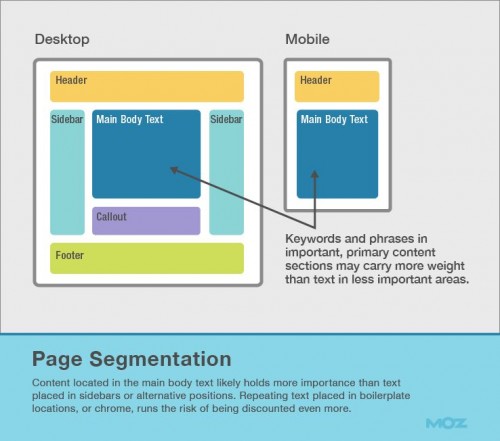
ページ分割は、ページの一部が隠れてしまうことが多く、モバイルデバイスの場合にはさらに大幅にその重要性を増してくる。検索エンジンは、あなたのページの中で、目につき、重要な部分をユーザーに提供しようとするため、これらの部分のテキストには最大の注目が集まるようにするべきである。
さらに一歩前進するために、HTML5では<article>、<aside>、および<nav>といった、ウェブページ上のセクションを明確に定義することのできる、意味論的な要素が強化されている。
内部的な最適化の場合、意味論的距離はテキスト内の様々な単語や語句間の関係性を指す。語句間の物理的な距離とは異なり、これは、単語がいかにして文章内、段落内、およびその他のHTML要素内に関連するのかに対するものである。
検索エンジンは、「ラブラドール」と「犬種」が同じ文章内にないときに、いかにしてその関連性を検知するのだろうか?
検索エンジンは、異なるHTML要素内の様々な単語と語句間の距離を測定することでこの問題を解決する。意味論的な概念が近ければ近いほど、概念の関連付けも近くなるのである。同じ段落内に位置する語句は、いくつかのテキストのブロックに離された語句よりも意味論的により近い。
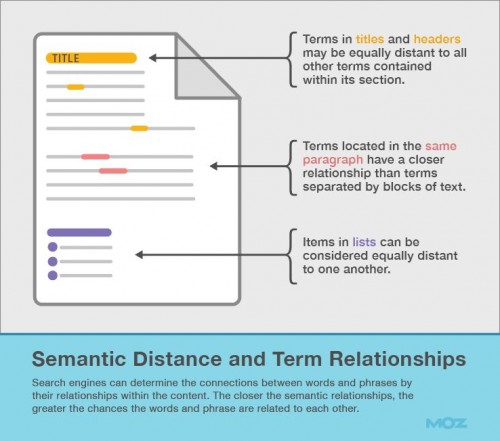
さらに、HTML要素は、複数の概念を引き寄せることで、概念間の意味論的距離を短縮できる場合がある。たとえば、リスト項目の互いの距離は同等と見なされ、「ドキュメントのタイトルはそのドキュメント内のその他全ての単語と近いと考えられる」のだ。
ここまでは個別のキーワードとキーワード間の関連性について説明してきた。検索エンジンは、完全な語句に基づいてページのインデックス作成を行い、また、これらの語句の関連性にもとづいてページのランキングを行うアプローチを取っている。
このプロセスは、語句に基づいたインデクシングとして知られている。
このプロセスの最も興味深い点は、Googleがいかにしてウェブページ上の重要な語句を決めるのかではなく、Googleがいかにしてこれらの語句の関連性に基づいてウェブページをランキングするのに語句を使用しているのかということだ。
検索エンジンは共起性の概念を適用することで、特定の語句がその他の語句を予測する傾向があることを知るのだ。あなたのウェブページの主題が「John Oliver」をターゲットにしたものだとすると、この語句は「真夜中のコメディアン」、「Daily Show」、や「HBO」といった語句と共起することが多い。これらの関連語句を含んだページは、それらを含まないページよりも「John Oliver」に関するページである可能性が高いのだ。
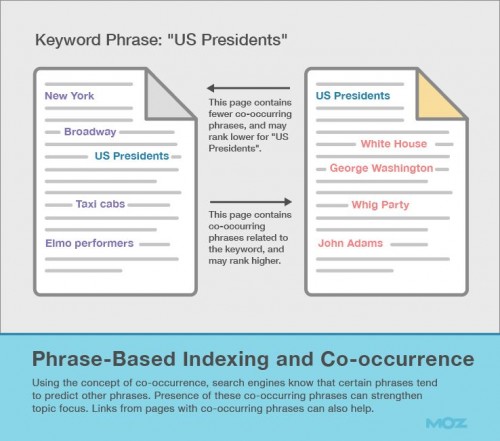
また、関連する共起表現を含むページからのインバウンドリンクに加えると、あなたのウェブページに強力な文脈的なシグナルを発することができるようになるのだ。
検索エンジンは、未来を見据えてトピック上の関連性を判定できるよう、キーワードに限らず、エンティティ間の関連性を活用する方法を検討している。
Googleの研究論文として公表された手法の1つでは、エンティティの特徴を通じた関連性の割り当てを説明している。
エンティティの特徴は、ドキュメント内の既知のエンティティ間の関連性を活用することで関連語句を見つけるという点で、TF-IDF法のような従来のキーワードに関するテクニックを超越している。エンティティとはドキュメント内に特徴的で、明確に定義されているものの全てを指す。
あるページ内のあるエンティティの他のエンティティへの関連性が強ければ強いほど、そのエンティティの重要性が増すのだ。
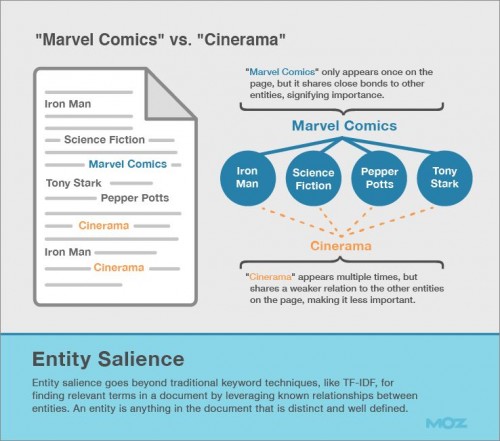
上記の図表の記事ではIron Man、Tony Stark、Pepper PottsとSFというトピックが含まれている。「Marvel Comics」という語句にはこれらの単語全てとの強力なエンティティ関連性がある。表示回数が1度だけであっても、そのドキュメント内での重要性は同等である。
その一方、「Cinerama」という語句が複数に渡り表示されている(この映画が上映されていた映画館)が、この語句のエンティティ関連性は弱く、同様に重要性も低いものになっている。
ただ単にキーワードを配置するというところから、より高度なトピックターゲティングに移行するにあたり、これらの概念を我々のウェブページのコンテンツに組み込むことは実際には簡単なことのだ。我々の多くは、意味論的な関連性およびエンティティの実現値を計算するための手段がないが、そのような手段がなくても、最適化されたコンテンツを作成するのに使用できるシンプルな方法が多数ある。
結局のところ、コンテンツを改善したり、理解しやすくするためにスーパーコンピューターなどは要らないということなのだ。我々が人間のために人間が用意したもののようにコンテンツを書けば、検索エンジン用に最適化に非常に大きな役割を果たす。あなたの内部的SEOとトピックターゲティングの最高のヒントはなんだろう?
この記事のために画像を提供してくださったDawn Shepard氏に心から感謝する。


この記事をご覧いただいている皆様へ。 このページは、SEO情報ブログ「ディーエムソリューションズの社員が作った、【SEOまとめ】」にて公開さ…

この記事をご覧いただいている皆様へ。 このページは、SEO情報ブログ「ディーエムソリューションズの社員が作った、【SEOまとめ】」にて公開さ…

SEOという言葉をご存知でしょうか。SEOとは、Search Engine Optimizationの略で、Yahoo! JAPANやGoo…

Webサイトへの集客は、どんな企業にとっても重要なものです。 リスティング広告・ディスプレイ広告・コンテンツマーケティングなど手法は多々あり…

Webサイトやメディアのコンテンツを制作し、Google(検索エンジン)に表示されるようにするには、Googleからクローリングしてもらう必…

SEO対策やサイト・ブログ運用をしていると「インデックス」というワードをよく耳にする方が多いのではないでしょうか?インデックスは、これからも…





今話題のAIによるコンテンツ自動生成機能も!SEO対策に本当に必要な機能だけを搭載した使いやすさとコストパフォーマンスに優れたWeb集客支援ツールです。
Webマーケティングに関わる施策全般をワンストップで
ご提供します。
お気軽にご相談ください。
Webマーケティング最新ニュースのレポートや無料セミナーの先行案内が届く、お得なメルマガ配信中!



 Hummingbirdでは、共起性は、そのような置換が実施され高度化された可能性があるクエリに対する特定のページの選択に関する特定の規則に従うと同時に、特定のコンテキストにおいて互いに類義語である可能性のある単語を識別するのに使用されている。
Hummingbirdでは、共起性は、そのような置換が実施され高度化された可能性があるクエリに対する特定のページの選択に関する特定の規則に従うと同時に、特定のコンテキストにおいて互いに類義語である可能性のある単語を識別するのに使用されている。 検索順位で1位まで上げるためのSEOポイント8つ
検索順位で1位まで上げるためのSEOポイント8つ E-E-A-Tとは? SEOにおける重要性と評価の高め方を解説
E-E-A-Tとは? SEOにおける重要性と評価の高め方を解説 成功確率アップ!BtoBのコンテンツマーケティング施策とは
成功確率アップ!BtoBのコンテンツマーケティング施策とは YMYLとは?該当するジャンルとSEOにおける対策のポイント8つ
YMYLとは?該当するジャンルとSEOにおける対策のポイント8つ SEO内部施策とは?重要な項目16選【セルフチェックリストつき】
SEO内部施策とは?重要な項目16選【セルフチェックリストつき】